3 Integrate Your Data with Other Data
Biodiversity data are collected and managed in many different systems and environments from museum collections, to environmental monitoring programs, research programs, or community science projects (e.g. iNaturalist). Data are often heterogeneous within and across these systems, depending on research objectives, but there are consistent themes in them: the what, where, and when. Although the details may have names unique to your own data, there are specific field names to use to provide these details in a way that aligns with others’ data. Through the use of common terminology, downstream users can not only better search for and discover data, but also evaluate, integrate, and compare datasets.
3.1 Darwin Core 🐘
What Is It?
Darwin Core (DwC) is a data standard that offers a stable, simple, and flexible framework for compilation and reuse of biodiversity data, including observations, specimens, samples, and related information, from varied and variable sources. DwC builds upon Dublin Core, a set of metadata terms used by libraries to describe physical and digital resources, to describe biological occurrences. The DwC glossary of terms provides identifiers, labels, and definitions to map occurrence information from multiple sources in a cohesive and interpretable way.
A single dataset, known as the Darwin Core Archive (DwC-A), is a compressed (e.g. zip) file that contains interconnected text files (e.g. csv or tsv) with DarwinCore standard-mapped data that are arranged into core files. To facilitate human- and machine-interpretation of the data, xml files are included to describe the contents of the Archive, the relationships between the core files and connected tables contained in the DwC-A.
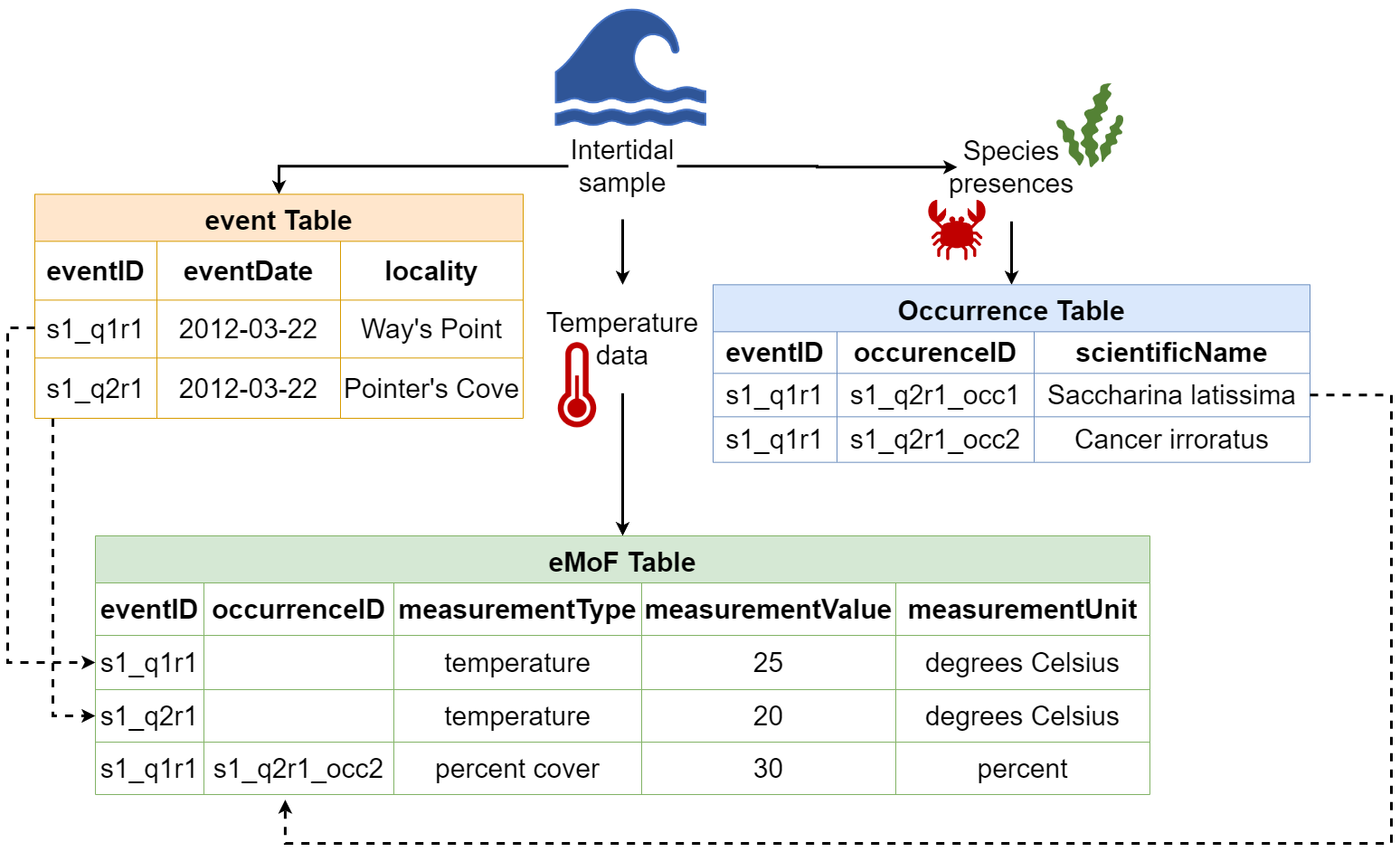 Darwin Core offers a solution for standardizing a simple group of observations about sampling, biological occurrences, environmental parameters, etc. Credit: Ocean Biodiversity Information System (OBIS) Manual. https://manual.obis.org/
Darwin Core offers a solution for standardizing a simple group of observations about sampling, biological occurrences, environmental parameters, etc. Credit: Ocean Biodiversity Information System (OBIS) Manual. https://manual.obis.org/
Why?
Any observation of an organism can be standardized to Darwin Core irrespective of the observing method by which the data were collected (e.g., observational data, genomics, imaging, animal tracking).
The Darwin Core standard plays a fundamental role in facilitating open-access biodiversity data sharing, use, and reuse. The Global Biodiversity Information Facility (GBIF), Ocean Biodiversity Information System (OBIS), the Atlas of Living Australia (ALA), and many more repositories use this data standard.
Aligning your data to DwC facilitates the use of heterogeneous biological data gathered using disparate collection methods.
Top Resources
Wieczorek et al., (2012) Darwin Core: An Evolving Community-Developed Biodiversity Data Standard.
Biddle, M., Benson, A., van der Stap, T., Pye, J., Murray, T., Lawrence, E., & Formel, S. (2024). Marine data mobilization workshop (Version 2024). Zenodo. https://doi.org/10.5281/zenodo.11085142
Recorded presentation by John Wieczorek about Darwin Core in April 2022.
3.2 Climate and Forecast (CF) 🌍
What Is It?
The Climate and Forecast (CF) Conventions clarify spatial and temporal contextual details of data. Put simply, CF terms include a name, description, and units. For example, they may include where data occur (e.g. land, water, atmosphere), quantities (e.g. concentrations, fluxes), and other qualifying features. By clarifying the context and specific quantities that variables represent, users can determine which are comparable. Thus, CF Conventions enable the integration of data from multiple sources.
Because the CF Conventions were designed to describe spatial and temporal aspects of Earth science data rather than to describe biological data specifically, their use is sometimes less intuitive than other conventions. Regardless, terms from CF are often useful in applications of biological data (e.g. observational gridded data, meteorological time series, satellite data, and watershed and river segment data).
Like many standards, CF is built on other standards. For example, units are specified using the UDUNITS system and files formats are defined by the netCDF (Network Common Data Form) standard. These standards have been around for about 30 years, and have facilitated the efficient processing and sharing of climate and oceanographic data.
Why?
If you’re a biologist who works in the realm of oceanography and climate science, familiarity with CF is useful for working with data from the National Centers for Environmental Information (NCEI) and NASA EarthData repositories (For a longer list or repositories, see here)
CF is a reasonably long-lived and tested standard. It has lasted through the ups and downs of technological and scientific progress, which is a tribute to the utility of the standard and the community behind it.
Top Resources
The NERC Vocabulary Server hosts CF and maps it to other vocabularies.
To find standard names that describe your data, open up the latest Standard Name table (as HTML or XML) and search through it for words typically used for your data.
CF is developed and maintained by the community using GitHub. To propose changes, ask questions, see the CF GitHub repositories.
For more information, see overviews of CF as a presentation and paper.
Recorded presentation by Roy Lowry about CF in April 2022.